We talked in a recent blog post about Hydra which is one the core layer 2 scaling technologies which will be rolling out for Cardano this year. Another part of the scaling puzzle is pipelining which John Woods (Director of Cardano Architecture) covers in a recent blog post.
Pipelining – or more precisely, diffusion pipelining – is an improvement to the consensus layer that facilitates faster block propagation. It enables even greater gains in headroom, which will enable further increases to Cardano’s performance and competitiveness.
https://iohk.io/en/blog/posts/2022/02/01/introducing-pipelining-cardanos-consensus-layer-scaling-solution/#
He explains:
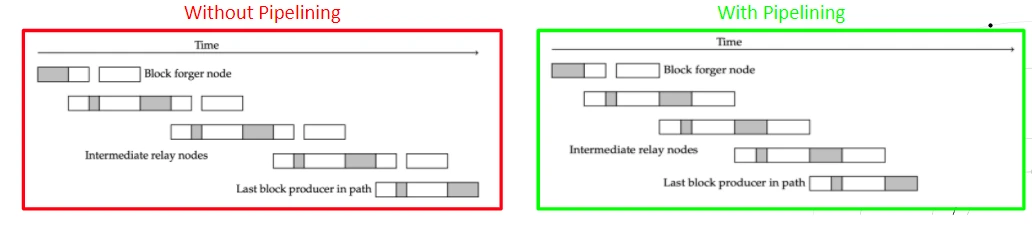
A block’s journey is a very serialized one. All steps happen in the same sequence every time, at every node. Considering the volume of nodes and the ever-growing number of blocks, block transmission takes a considerable amount of time.
Diffusion pipelining overlays some of those steps on top of each other so they happen concurrently. This saves time and increases throughput.
As ever care is being taken on the rollout:
One of the design principles behind diffusion pipelining was to achieve faster block propagation while avoiding ‘destructive’ changes to the chain. We did not want to remove any of the protocols, primitives, or interactions already happening in Cardano, because nodes rely on these established mechanisms.
This is a great example of the build then optimise strategy that also underpins the approach to Unix (and Linux). Rob Pike, who became one of the great masters of C, offers these rules on optimisation in Notes on C Programming [Pike]:
Rule 1. You can’t tell where a program is going to spend its time. Bottlenecks occur in surprising places, so don’t try to second guess and put in a speed hack until you’ve proven that’s where the bottleneck is.
Rule 2. Measure. Don’t tune for speed until you’ve measured, and even then don’t unless one part of the code overwhelms the rest.
Rule 3. Fancy algorithms are slow when
nis small, andnis usually small. Fancy algorithms have big constants. Until you know thatnis frequently going to be big, don’t get fancy. (Even ifndoes get big, use Rule 2 first.)Rule 4. Fancy algorithms are buggier than simple ones, and they’re much harder to implement. Use simple algorithms as well as simple data structures.
Rule 5. Data dominates. If you’ve chosen the right data structures and organized things well, the algorithms will almost always be self-evident. Data structures, not algorithms, are central to programming.
Rule 6. There is no Rule 6.
Ken Thompson, the man who designed and implemented the first Unix, reinforced Pike’s rule 4 with a gnomic maxim worthy of a Zen patriarch:
When in doubt, use brute force.
You might start to notice more similarities to these rules in the pragmatic approach Cardano brings to its implementation and tuning.
Till next time….